您现在的位置是:首页 > 研究生趋势
数据清洗与数据标注
研思启迪坊
2025-07-13【研究生趋势】194人已围观
简介数据清洗定义:数据清洗(DataCleaning),又称数据清理,是指从数据集中移除或修正错误、无效、不一致和重复的数据,以提高数据质量和可靠性。目的:数据准确性:确保数据真实、准确无误。数据完整性:填补数据缺失,确保数据集完整。数据一致性:标准化数据格式,保证不同数据集之间的一致性。数据可靠性:移...

定义:数据清洗(DataCleaning),又称数据清理,是指从数据集中移除或修正错误、无效、不一致和重复的数据,以提高数据质量和可靠性。
目的:
数据准确性:确保数据真实、准确无误。
数据完整性:填补数据缺失,确保数据集完整。
数据一致性:标准化数据格式,保证不同数据集之间的一致性。
数据可靠性:移除不可靠和无效的数据,提高数据的可信度。
提高分析和模型性能:高质量的数据有助于更准确的分析和更可靠的机器学习模型。
场景:
数据分析和报告:确保数据准确、完整和一致。
机器学习和模型训练:保证训练数据的质量。
客户关系管理(CRM)系统:确保客户信息的准确性。
数据迁移:从一个系统迁移到另一个系统时。
常见数据清洗步骤:
移除重复数据:删除数据集中重复的记录。
处理缺失值:填补或移除缺失的数据。
修正错误数据:纠正数据中的错误值(如拼写错误、无效值等)。
数据标准化:统一数据的格式(如日期格式、单位转换等)。
检测和处理异常值:识别并处理数据中的异常值。
数据转换:将数据转换为适合分析或模型训练的格式。
工具和平台:
Excel:最早的数据清洗工具之一,方便上手,适合小规模数据清洗。
OpenRefine:开源工具,强大的数据转换和清洗能力。
Tal:提供数据集成和清洗功能,支持大数据平台。
Trifacta:数据准备和清洗平台,基于云计算,适合大规模数据处理。
Apache家族
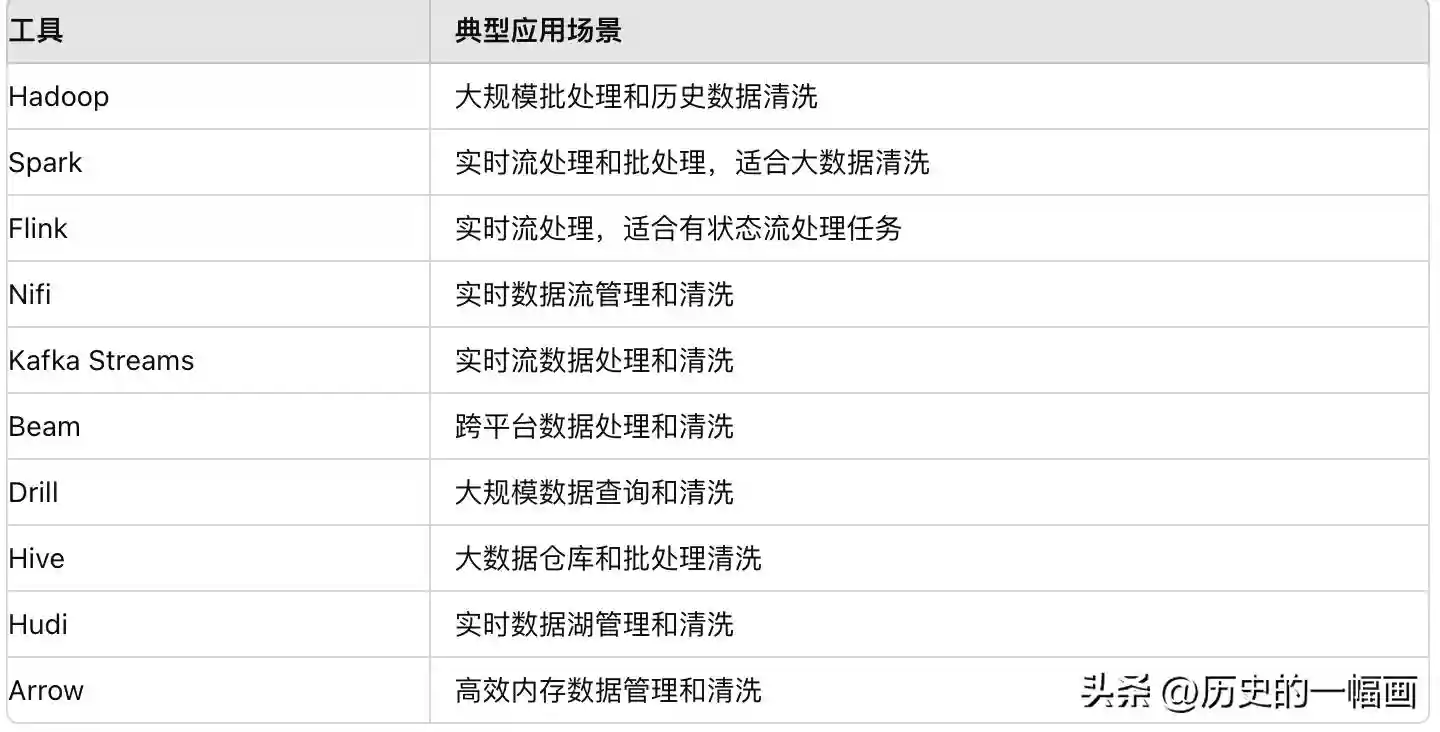
目的:
提供训练数据:为机器学习模型提供有标签的训练数据。
提高模型性能:帮助模型学习数据中的模式,提高模型的准确性和效果。
验证和测试:使用标注数据评估模型性能,确保模型的可靠性和稳定性。
数据丰富度:通过标注丰富数据的特征,提供更多信息供模型学习。
场景:
自然语言处理(NLP):例如情感分析、实体识别。
计算机视觉:例如图像分类、目标检测。
语音识别:例如语音转文字、情感识别。
推荐系统:例如标签推荐、内容推荐。
自动驾驶:例如路况识别、物体识别。
常见数据标注类型:
文本标注:
情感分析:为文本添加情感标签(如正面、负面、中性)。
实体识别:标注文本中的实体(如人名、地名、组织名等)。
语义分类:将文本分类到不同类别中(如新闻分类、主题分类等)。
图像标注:
图像分类:为图像添加类别标签。
目标检测:标注图像中目标的位置和类别(如物体检测、面部识别等)。
图像分割:标注图像中不同区域的边界。
音频标注:
语音转文字:将音频中的语音内容转写为文字。
语音情感识别:为音频添加情感标签(如高兴、悲伤、愤怒等)。
声音分类:将音频分类到不同类别中(如音乐、噪音、人声等)。
工具和平台:
LabelImg:开源图像标注工具。
Labelbox:数据标注平台,支持多种标注任务,收费。
Supervisely:基于云的计算机视觉数据标注平台,收费。
AmazonSageMakerGroundTruth:AWS提供的数据标注服务,收费。
Appen:数据标注和人工智能培训数据服务平台,收费。
阿里云DataWorks:提供了数据标注的功能,支持文本、图像、语音等多种数据类型的标注。用户可以通过可视化界面进行标注任务的管理和分发。收费。
很赞哦!(2)







